前言
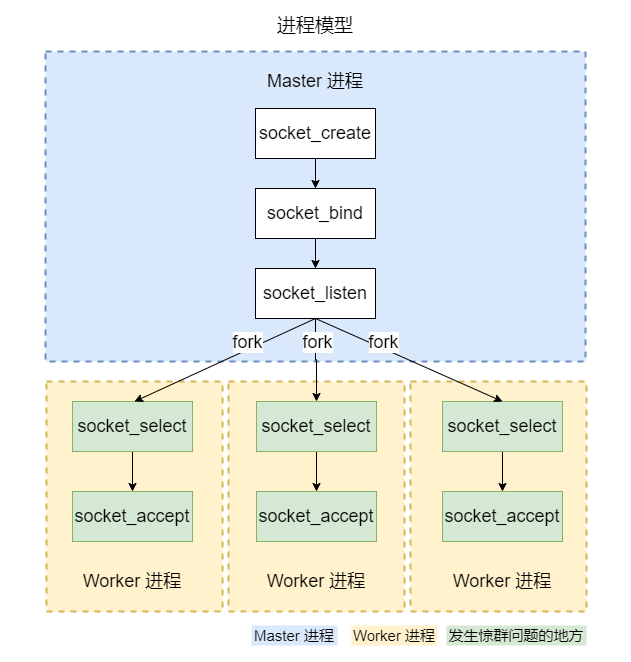
我们知道,像 Nginx、Workerman 都是单 Master 多 Worker 的进程模型。
Master 进程用于创建监听套接字、创建 Worker 进程及管理 Worker 进程。
Worker 进程是由 Master 进程通过 fork 系统调用派生出来的,所以会自动继承 Master 进程的监听套接字,每个 Worker 进程都可以独立地接收并处理来自客户端的连接。
由于多个 Worker 进程都在等待同一个套接字上的事件,就会出现标题所说的惊群问题。
什么是惊群问题
惊群问题又称惊群效应,当多个进程等待同一个事件,事件发生后内核会唤醒所有等待中的进程,但是只有一个进程能够获得 CPU 执行权对事件进行处理,其他的进程都是被无效唤醒的,随后会再次陷入阻塞状态,等待下一次事件发生时被唤醒。
举个例子,你们寝室几个人都在一边睡觉一边等外卖,外卖到了的时候,快递小哥嗷一嗓子把你们几个人都叫醒了,但是他只送了一个人的外卖,其它人骂骂咧咧的又躺下了,下次外卖来的时候,又会把这几个人都吵醒。
这里的室友表示进程,外卖小哥表示操作系统,外卖就是等待的事件。
惊群问题带来的问题
由于每次事件发生会唤醒所有进程,所以操作系统会对多个进程频繁地做无效的调度,让 CPU 大部分时间都浪费在了上下文切换上面,而不是让真正需要工作的进程运行,导致系统性能大打折扣。
发生惊群问题的时机
通过上面的介绍可以知道,惊群问题主要发生在 socket_accept 和 socket_select 两个函数的调用上。
下面我们通过两个例子复现这两个系统调用的惊群。
socket_accept 函数
PHP 中的 socket_accept 函数是 accept 系统调用的一层包装。函数原型如下:
socket_accept(Socket $socket): Socket|false
该函数接收监听套接字上的新连接,一旦接收成功,就会返回一个新的套接字(连接套接字)用于与客户端进行通信。如果没有待处理的连接,socket_accept 函数将阻塞,直到有新的连接出现。
// 创建 TCP 套接字
$server_socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP);
// 将套接字绑定到指定的主机地址和端口上
socket_bind($server_socket, "0.0.0.0", 8080);
// 设置为监听套接字
socket_listen($server_socket);
printf("master[%d] running\n", posix_getpid());
for ($i = 0; $i < 5; $i++) {
$pid = pcntl_fork();
if ($pid < 0) {
exit('fork 失败');
} else if ($pid == 0) {
// 这里是子进程
$pid = posix_getpid();
printf("worker[%d] running\n", $pid);
// while true 是为了处理完一个连接之后,可以继续处理下一个连接
while (true) {
// 由于我们刚刚创建的 $server 是阻塞 IO,
// 所以代码运行到这的时候会阻塞住,会将 CPU 让出去,
// 直到有客户端来连接
$conn_socket = socket_accept($server_socket);
if (!$conn_socket) {
printf("worker[%d] 接收新连接失败,原因:%s\n", $pid, socket_last_error($conn_socket));
continue;
}
// 获取客户端地址及端口号
socket_getpeername($conn_socket, $address, $port);
printf("worker[%d] 接收新连接成功:%s:%d\n", $pid, $address, $port);
// 关闭客户端连接
socket_close($conn_socket);
}
}
// 这里是父进程
}
// 父进程等待子进程退出,回收资源
while (true) {
// 为待处理的信号调用信号处理程序。
\pcntl_signal_dispatch();
// 暂停当前进程的执行,直到一个子进程退出,或者直到一个信号被传递。
$pid = \pcntl_wait($status, WUNTRACED);
// 再次调用待处理信号的信号处理程序。
\pcntl_signal_dispatch();
if ($pid > 0) {
printf("worker[%d] 退出\n", $pid);
}
}
上面的代码先创建了一个监听套接字 $server_socket,然后通过 pcntl_fork 函数派生出 5 个子进程。 在调用完 pcntl_fork 函数后,如果派生子进程成功,那么该函数会有两个返回值,在父进程中返回子进程的进程 ID,在子进程中返回 0;派生失败则返回 -1。
- 父进程:调用 pcntl_wait 函数阻塞等待子进程退出,然后回收进程资源
- 子进程:调用 socket_accept 函数并阻塞,直到有新连接需要处理。
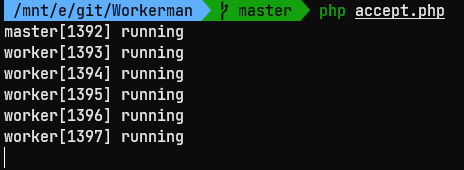
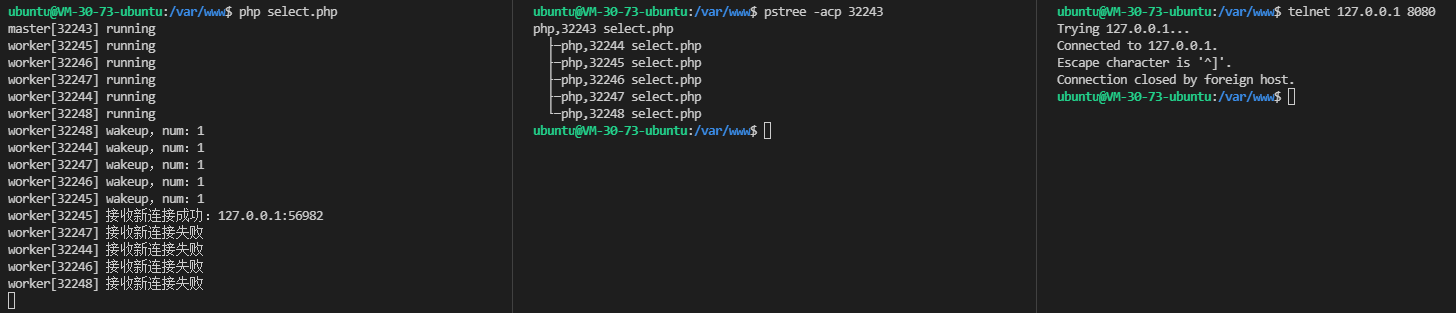
将上面的代码保存为 accept.php,然后在 CLI 中执行 php accept.php 启动服务端程序,可以看到 1 个 master 进程和 5 个 worker 进程都已经处于运行状态:
执行 pstree -acp pid 查看一下进程树:
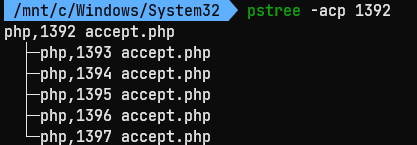
进程树的结构与我们服务启动的日志是一致的。
接下来我们执行 telnet 0.0.0.0 8080 命令连接到服务端程序上,accept.php 输出:
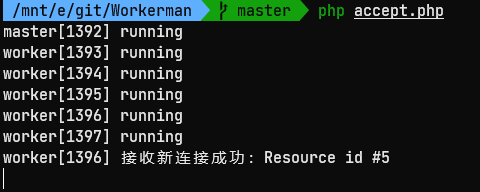
咦,怎么回事,跟一开始说的不一样啊,这明明只有一个进程被唤醒然后处理了新连接!
莫慌,这是在预料之中的,因为在 Linux 2.6 后的版本中,Linux 已经修复了 accept 的惊群问题。
演示这一步主要是为后面的内容做铺垫。
socket_select 函数
跟 socket_accept 函数一样,socket_select 函数也是 select 系统调用的一层包装。
select 是最早的一种多路复用实现方式,性能相对于后面出现的 poll、epoll 要差很多,那么为什么这里要用 select 来做演示呢?
一是因为支持 select 的操作系统比较多,连 Windows 和 MacOS 也都支持 select 系统调用。 二是截止目前 Linux 内核版本 4.4.0 依然没有解决 select 的惊群问题。
socket_select 接受套接字数组并阻塞等待它们有事件发生。函数原型如下:
socket_select(
array|null &$read,
array|null &$write,
array|null &$except,
int|null $seconds,
int $microseconds = 0
): int|false
- $read 表示需要监听可读事件的套接字数组。
- $write 表示需要监听可写事件的套接字数组。
- $except 表示需要监听的异常事件套接字数组。
- $seconds 和 $microseconds 组合起来表示 select 阻塞超时时间,$seconds 为 0 表示不等待,立即返回,设置为 null 表示一直阻塞等待,直到有事件发生。
当在函数超时前有事件发生时,返回值为发生事件的套接字数量,如果是函数超时,返回值为 0 ,有错误发生时返回 false。
socket_select 函数的示例程序与上面 socket_accept 函数的差不多,只不过需要将监听套接字设置为非阻塞,然后在 socket_accept 函数之前调用 socket_select 进行阻塞等待事件。
// 创建 TCP 套接字
$server_socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP);
// 将套接字绑定到指定的主机地址和端口上
socket_bind($server_socket, "0.0.0.0", 8080);
// 设置为监听套接字
socket_listen($server_socket);
// 设置为非阻塞
socket_set_nonblock($server_socket);
printf("master[%d] running\n", posix_getpid());
for ($i = 0; $i < 5; $i++) {
$pid = pcntl_fork();
if ($pid < 0) {
exit('fork 失败');
} else if ($pid == 0) {
// 这里是子进程
$pid = posix_getpid();
printf("worker[%d] running\n", $pid);
// while true 是为了处理完一个连接之后,可以继续处理下一个连接
while (true) {
// 将监听套接字放入可读事件的套接字数组中,
// 表示我们需要等待监听套接字上的可读事件,
// 监听套接字发生可读事件说明有客户端连接上来了。
$reads = [$server_socket];
// 可写事件和异常事件我们不关心,设置为空数组即可。
$writes = $excepts = [];
// 超时时间设置为 NULL,表示一直阻塞等待,直到有事件发生。
$num = socket_select($reads, $writes, $excepts, NULL);
printf("worker[%d] wakeup,num:%d\n", $pid, $num);
$conn_socket = socket_accept($server_socket);
if (!$conn_socket) {
printf("worker[%d] 接收新连接失败\n", $pid);
continue;
}
// 获取客户端地址及端口号
socket_getpeername($conn_socket, $address, $port);
printf("worker[%d] 接收新连接成功:%s:%d\n", $pid, $address, $port);
// 关闭客户端连接
socket_close($conn_socket);
}
}
// 这里是父进程
}
// 父进程等待子进程退出,回收资源
while (true) {
// 为待处理的信号调用信号处理程序。
\pcntl_signal_dispatch();
// 暂停当前进程的执行,直到一个子进程退出,或者直到一个信号被传递。
$pid = \pcntl_wait($status, WUNTRACED);
// 再次调用待处理信号的信号处理程序。
\pcntl_signal_dispatch();
if ($pid > 0) {
printf("worker[%d] 退出\n", $pid);
}
}
我们将上述代码保存为 select.php 并执行 php select.php 启动服务,然后使用 telnet 127.0.0.1 8080 连接上去就会发现 5 个子进程都输出了 wakeup,但是只有一个进程 accept 成功了。
如何解决惊群问题
因为惊群问题主要是出在系统调用上,但是内核系统更新肯定没那么及时,而且不能保证所有操作系统都会修复这个问题。
所以解决方案可以分为两类:用户程序层面和内核程序层面,用户程序层面就是通过加锁解决问题,内核程序层面就是让内核程序提供一些机制,一劳永逸地解决这个问题。
用户程序:加锁
通过上面我们可以知道,惊群问题发生的前提是多个进程监听同一个套接字上的事件,所以我们只让一个进程去处理监听套接字就可以了。
Nginx 采用了自己实现的 accept 加锁机制,避免多个进程同时调用 accept。Nginx 多进程的锁在底层默认是通过 CPU 自旋锁实现的,如果操作系统不支持,就会采用文件锁。
Nginx 事件处理的入口函数使 ngx_process_events_and_timers(),下面是简化后的加锁过程:
// 是否开启 accept 锁,
// 开启则需要抢锁,以防惊群,默认是关闭的。
if (ngx_use_accept_mutex) {
if (ngx_accept_disabled > 0) {
// ngx_accept_disabled 的值是经过算法计算出来的,
// 当值大于 0 时,说明此进程负载过高,不再接收新连接。
ngx_accept_disabled--;
} else {
// 尝试抢 accept 锁,发生错误直接返回
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
if (ngx_accept_mutex_held) {
// 抢到锁,设置事件处理标识,后续事件先暂存队列中。
flags |= NGX_POST_EVENTS;
} else {
// 未抢到锁,修改阻塞等待时间,使得下一次抢锁不会等待太久
if (timer == NGX_TIMER_INFINITE
|| timer > ngx_accept_mutex_delay)
{
timer = ngx_accept_mutex_delay;
}
}
}
}
在 ngx_trylock_accept_mutex 函数中,如果抢到了锁,Nginx 会把监听套接字的可读事件放入事件循环中,该进程有新连接进来的时候就可以 accept 了。
内核程序:从根源解决问题
在高本版的 Nginx 中 accept 锁默认是关闭的,如果开启了 accept 锁,那么在多个 worker 进程并行的情况下,对于 accept 函数的调用是串行的,效率不高。
所以最好的方式还是让内核程序解决惊群的问题,从问题的根源上去解决。
Linux 内核 3.9 及后续版本提供了新的套接字参数 SO_REUSEPORT,该参数允许多个进程绑定到同一个套接字上,内核在收到新的连接时,只会唤醒其中一个进程进行处理,内核中也会做负载均衡,避免某个进程负载过高。
对于 epoll 多路复用机制,Linux 内核 4.5+ 新增 EPOLLEXCLUSIVE 标志,这个标志会保证一个事件只会有一个阻塞在 epoll_wait 函数的进程被唤醒,避免了惊群问题。
在 Nginx 的 ngx_event_process_init 函数中,可以看到 Nginx 是如何使用 SO_REUSEPORT 和 EPOLLEXCLUSIVE 的。
// Nginx 支持端口复用
#if (NGX_HAVE_REUSEPORT)
// 配置 listen 80 resuseport 时,支持多进程共用一个端口,
// 此时可直接把监听套接字加入事件循环中,并监听可读事件。
if (ls[i].reuseport) {
if (ngx_add_event(rev, NGX_READ_EVENT, 0) == NGX_ERROR) {
return NGX_ERROR;
}
continue;
}
#endif
// 打开 accept_mutex 锁之后,
// 每个 worker 进程不能直接处理监听套接字,
// 需要在 worker 进程抢到锁之后才能将监听套接字放入自己的事件循环中。
if (ngx_use_accept_mutex) {
continue;
}
// Nginx 支持 EPOLLEXCLUSIVE 标志
#if (NGX_HAVE_EPOLLEXCLUSIVE)
// 如果 nginx 使用的是 epoll 多路复用机制,并且 worker 进程大于 1,
// 那么就将监听套接字加入自己的事件循环中,并且设置 EPOLLEXCLUSIVE 标志。
if ((ngx_event_flags & NGX_USE_EPOLL_EVENT)
&& ccf->worker_processes > 1)
{
if (ngx_add_event(rev, NGX_READ_EVENT, NGX_EXCLUSIVE_EVENT)
== NGX_ERROR)
{
return NGX_ERROR;
}
continue;
}
#endif
// 未开启 accept_mutex 锁,未启动 resuseport 端口复用,不支持 EPOLLEXCLUSIVE 标志,
// 此后监听套接字发生事件时会引发惊群问题。
if (ngx_add_event(rev, NGX_READ_EVENT, 0) == NGX_ERROR) {
return NGX_ERROR;
}
总结
通过本文我们了解到什么是惊群问题,以及对应的解决方式。在编写类似的多进程的应用时就可以避免这个问题,从而提高应用的性能。