前言
早在去年 11 月底就已经看过《PHP 实现 Base64 编码/解码》这篇文章了,由于当时所掌握的位运算知识过于薄弱,所以就算是看过几遍也是囫囵吞枣一般,不出几日便忘记了其滋味。
只得其形,不知其意。
所以暗下决心写一篇阅读笔记,以此来较量是否掌握了其原理及位运算相关知识。但是作为一名拖延症患者,导致此事一再拖延,直至今日。
人总是趋利避害的。
记得刚出来实习的时候,室友大牛会截图问我一些代码是什么意思。我跟他说,你一行行的读,一边读一边写注释,等你读完就知道这些代码是什么意思。
对于一坨不认识的代码,首先是抗拒,但是为了生活又不得不做,于是开始烦躁起来,选择寻求他人或者搁置一旁。遇到这种情况,按照上面的方法一行行的写注释,写着写着心就静了下来,代码也理解了,既不麻烦他人也完成了任务。
放假前,在《C Primer Plus》一书中阅读了关于位运算的章节,对于位运算的一些概念有了基本的认识,所以当静下心来阅读《PHP 实现 Base64 编码/解码》文中的代码时,也还算是顺畅。
由于文中一些位运算代码十分巧妙,所以在阅读代码的时候也是一边写注释一边读,为了便于查看,带注释的代码放在文末。
Base64 字符映射表
这张表包含了 64 个字符,Base64 编码后的结果也是取自于这 64 个字符,每个字符用 6 位的二进制来表示。
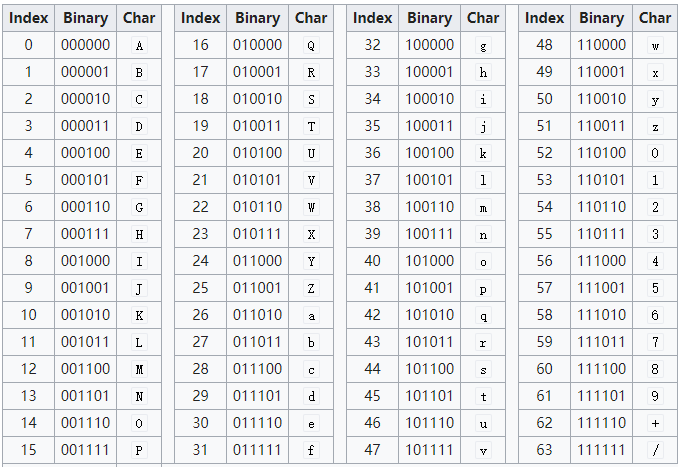
通过这张映射表,可以根据 Binary 找到对应的 Char,Index 的二进制去掉左侧两位就是 Binary 了。
举个例子,Index 51 的二进制是 00110011,一共有 8 位,去掉左侧两位就是 110011,对应的 Char 是 z;
Base64 编码的过程
假设现有字符串 123 需要编码,首先将每个字符的 ASCII 转成二进制后排列在一起。
// 1 的 ASCII 为 49,49 的二进制为 00110001
// 2 的 ASCII 为 50,50 的二进制为 00110010
// 3 的 ASCII 为 60,60 的二进制为 00110011
// 将二进制排列在一起
001100010011001000110011
上面的二进制为 24 位,正好可以拆分为 4 个 6 位的 Base64 字符。
001100 010011 001000 110011
再根据上面映射表中的 Binary 找到对应的 Char。
001100 010011 001000 110011
M T I z
所以字符串 123 经过 Base64 之后就是 MTIz 了。
虽然上面已经将 Base64 编码的过程基本上说完了,但是还有个很重要的问题:如果字符串的长度不是 3 的倍数怎么办?
举个例子,需要加密的字符串为 1234,长度为 4,不是 3 的倍数,多出了一个字符。
排列后的二进制位为 32 位,组成 5 个 6 位的 Base64 字符后还多出 2 位,多出来的总不能丢掉不管吧?所以需要对多出来的位进行 补齐 处理。
怎么补呢?上面已经说过,6 位可以组成一个 Base64 字符,那么只要再补上 4 位就可以组成一个完整的Base64 字符。
在这里我们偷偷的给字符串加了 4 位,怎么在解码时候知道编码时加了 4 位呢?很简单,只需要在编码结果后面加上两个 = 号。
所以字符串 1234 的编码结果为 MTIzNA==。
上面举的例子是多出一个字符的情况,如果多出两个字符呢?还是一样做补齐处理,不过只需要补上 2 位,在编码结果后面加上一个 = 号。
Base64 编码的代码实现
为了突出重点,这里会将每部分的代码单独提出来,补充一些源码中并不存在的代码,使得代码块能够单独运行。
排列字符二进制
首先将每个字符的 ASCII 转为二进制并排列在一起。
// 需要编码的字符串
$content = '123';
// 先将第一个字符左移16位,为剩下2个字符(每个字符8位)腾出16位的空间
$int_24 = (ord($content[0]) << 16)
// 再将第二个字符左移8位,紧跟第一个字符后面
| (ord($content[1]) << 8)
// 最后一个字符放在剩下的8位里面
| (ord($content[2]) << 0);
先理解一下上面的注释,在脑海中留一个大致的印象,然后再往后看。
$content[0] 的值为 1,通过 ord() 函数获取到 ASCII 值为 49,49 的二进制值为 00110001,然后将其左移 16 位,得到的二进制为 001100010000000000000000。
左移多少位是在二进制的右边加多少个 0 ,可以数一下二进制 00110001 的右边是不是多了 16 个 0,这 16 个 0 就是为剩下的两个字符留的。
$content[1] 的值为 2,ASCII 值为 50,50 的二进制为 00110010,左移 8 位后的二进制为 0011001000000000,然后通过位或运算将其放入二进制 001100010000000000000000 中,得到二进制 001100010011001000000000。
001100010000000000000000 // 第一个字符 ASCII 码左移16位后
0011001000000000 // 第二个字符 ASCII 码左移8位后
001100010011001000000000 // 位或运算后
这样第二个字符的二进制就紧跟在第一个字符的二进制后面,这时后面还有空闲的 8 个 0 留给最后一个字符。
$content[2] 的值为 3,ASCII 为 60,60 的二进制为 00110011,然后使用位或运算直接放入上一步得到的二进制中。
001100010011001000000000 // 上一步得到的二进制
00110011 // 60 的二进制
001100010011001000110011 // 位或后
此时,$int_24 的二进制值为 001100010011001000110011。
觉得看不清的话可以 ctrl f 分别搜索一下三个字符 ASCII 的二进制。
转换为 Base64 字符
接下来将 $int_24 的二进制分为 4 个 6 位的二进制,然后再根据二进制转换为 Base64 字符。
// 通过 normalToBase64Char() 方法将6位的二进制转换为 base64 字符
$ret .= self::normalToBase64Char($int_24 >> 18);
$ret .= self::normalToBase64Char(($int_24 >> 12) & 0x3f);
$ret .= self::normalToBase64Char(($int_24 >> 6) & 0x3f);
$ret .= self::normalToBase64Char($int_24 & 0x3f);
先来看一下 4 个 6 位二进制获取的过程。
第一个 6 位二进制,将 $int_24 右移 18 位得到了二进制 001100,右移就是移除右侧多少个位。
001100010011001000110011 // $int_24 的二进制
001100 // 右移 18 位后
第二个 6 位二进制,将 $int_24 右移 12 位,再通过位与 0x3f 保留右侧的 6 位,得到二进制 010011。
001100010011001000110011 // $int_24 的二进制
001100010011 // 右移 12 位后
111111 // 0x3f 的十进制是63,二进制值是 111111
010011 // 位与运算后
第三个 6 位二进制,将 $int_24 右移 6 位,再通过位与 0x3f 保留右侧的 6 位,得到二进制 001000。
001100010011001000110011 // $int_24 的二进制
001100010011001000 // 右移 6 位后
111111 // 0x3f 的十进制是63,二进制值是 111111
001000 // 位与运算后
第四个 6 位二进制,将 $int_24 位与 0x3f 保留右侧的 6 位,得到二进制 110011。
001100010011001000110011 // $int_24 的二进制
111111 // 0x3f 的十进制是63,二进制值是 111111
110011 // 位与运算后
再来看看 normalToBase64Char() 方法,这个函数的作用就是将 6 位二进制表示的值转为 Base64 字符。
private static function normalToBase64Char($num)
{
if ($num >= 0 && $num <= 25) {
return chr(ord('A') + $num);
} else if ($num >= 26 && $num <= 51) {
return chr(ord('a') + ($num - 26));
} else if ($num >= 52 && $num <= 61) {
return chr(ord('0') + ($num - 52));
} else if ($num == 62) {
return '+';
} else {
return '/';
}
}
需要注意的是,这里的 $num 是上面分割出来的 6 位二进制表示的值,比如 001100 表示的值就是 12。$num 就是映射表中的 Base64 数值(Index)。
// 0b 表示001100是二进制的
echo 0b001100; // 12
通过映射表可以知道 001100 对应的是 M,那怎么给它们建立映射关系呢?
还是得从映射表中找规律,A 的 ASCII 值为 65,M 的 ASCII 值为 77,77 减 65 等于 12,正好是 001100 所表示的值。所以当 $num 的值大于等于 0,小于等于 25 时,$num 对应的 Base64 字符在 A ~ Z 之间,只需要将 $num 加上 A 的 ASCII 值 65 就可以得到对应的 Base64 字符了。
// 当 $num >= 0 && $num <= 25
// 0 的 6 位二进制为 000000
echo chr(ord('A') + 0b000000).PHP_EOL; // A
// 1 的 6 位二进制为 000001
echo chr(ord('A') + 0b000001).PHP_EOL; // B
// 2 的 6 位二进制位 000010
echo chr(ord('A') + 0b000010).PHP_EOL; // C
// 3 的 6 位二进制位 000011
echo chr(ord('A') + 0b000011).PHP_EOL; // D
通过上面我们可以知道 0 ~ 25 之间的 26 个数字分别对应 26 个 Base64 字符 A ~ Z,所以当 $num 大于 25 时,需要减去 26,得到的结果再加上 a 的 ASCII 值 97 就是对应的 Base64 字符的 ASCII 值。
// 当 $num >= 26 && $num <= 51
// 26 的 6 位二进制为 011010
echo chr(ord('a') + (0b011010 - 26)).PHP_EOL; // a
// 27 的 6 位二进制为 011011
echo chr(ord('a') + (0b011011 - 26)).PHP_EOL; // b
// 28 的 6 位二进制位 011100
echo chr(ord('a') + (0b011100 - 26)).PHP_EOL; // c
// 29 的 6 位二进制位 011101
echo chr(ord('a') + (0b011101 - 26)).PHP_EOL; // d
通过上面我们可以知道 26 ~ 51 之间的 26 个数字分别对应 26 个 Base64 字符 a ~ z, 所以在当 $num 大于 51 时,需要减去 52(26 个大写字母 + 26 个小写字母),得到的结果再加上 0 的 ASCII 值 48 就是对应的 Base64 字符的 ASCII 值。
// 当 $num >= 52 && $num <= 61
// 52 的 6 位二进制为 110100
echo chr(ord('0') + (0b110100 - 52)).PHP_EOL; // 0
// 53 的 6 位二进制为 110101
echo chr(ord('0') + (0b110101 - 52)).PHP_EOL; // 1
// 54 的 6 位二进制位 110110
echo chr(ord('0') + (0b110110 - 52)).PHP_EOL; // 2
// 55 的 6 位二进制位 110111
echo chr(ord('0') + (0b110111 - 52)).PHP_EOL; // 3
通过上面我们可以知道 52 ~ 61 之间的 10 个数字分别对应 10 个 Base64 字符 0 ~ 9。
当 $num 等于 62 时对应的 Base64 字符为 +,等于 63 时对应的 Base64 字符为 /。
到这里 normalToBase64Char() 方法就讲完了,将上面的 4 个 6 位二进制 001100、010011、001000、110011,传入方法中得到 M、T、I、z,所以 123 编码后就是 MTIz。
Base64 字符补齐
先看一下补齐处理的代码。
// 字符串长度
$len = strlen($content);
// 完整组合
$loop = intval($len / 3);
//剩余字符数,是否需要补齐
$rest = $len % 3;
if ($rest == 0) {
return $ret;
} else if ($rest == 1) {
// 如果多出1个字符,将其左移4位进行补齐
$int_12 = ord($content[$loop * 3]) << 4;
// 右移 6 位,剩余左侧 6 位
$ret .= normalToBase64Char($int_12 >> 6);
// 通过 0x3f (111111) 以掩码的方式取出右侧 6 位
$ret .= normalToBase64Char($int_12 & 0x3f);
$ret .= "==";
return $ret;
} else {
// 如果多出 2 个字符,需要补齐 2 位
// 先将多出来的第一个字符左移 8 位,为多出来的第二个字符腾出位置
// 然后再将整体向左移 2 位,使其可以拆分为 3 个 6 位的 base64 字符
$int_18 = ((ord($content[$loop * 3]) << 8) | ord($content[$loop * 3 + 1])) << 2;
// 右移 12 位,剩余左侧 6 位
$ret .= normalToBase64Char($int_18 >> 12);
// 右移 6 位,通过 0x3f (111111) 以掩码的方式取出剩余的右侧 6 位
$ret .= normalToBase64Char(($int_18 >> 6) & 0x3f);
// 通过 0x3f (111111) 以掩码的方式取出右侧 6 位
$ret .= normalToBase64Char($int_18 & 0x3f);
$ret .= "=";
return $ret;
}
如果 $rest 等于 0,说明字符串长度是 3 的倍数,不需要补齐。
如果 $rest 等于 1,说明多出一个字符,将其 ASCII 值左移 4 位,得到二进制位长度为 12 位,正好可以拆分为 2 个 6 位的二进制。
// 这里用 1234 进行举例,多出来的字符为 4
00110100 // 4 的 ASCII 值为 52,二进制为 00110100
001101000000 // 左移 4 位后
将 $int_12 右移 6 位,得到剩下的 6 位。
001101000000 // $int_12 的二进制
001101 // 右移 6 位后
$int_12 位与 0x3f 得到右侧的 6 位。
001101000000 // $int_12 的二进制
111111 // 0x3f 的十进制是63,二进制值是 111111
000000 // 位与运算后
最后在编码结果后面加上 ==,表示多出一个字符。
如果 $rest 等于 2,说明多出两个字符,先将第一个字符左移 8 位,为第二个字符腾出位置,再通过位或运算将第二个字符放在第一个字符后面,两个字符的 ASCII 值排列后将整体左移 2 位,得到二进制位长度为 18 位,可以拆分为 3 个 6 位的二进制。
// 这里用 12345 进行举例,多出来的字符为 45
00110100 // 4 的 ASCII 值为 52,二进制为 00110100
0011010000000000 // 将第一个字符左移 8 位后
00110101 // 5 的 ASCII 值位 53,二进制为 00110101
0011010000110101 // 位或运算后
001101000011010100 // 左移 2 位后
然后就是按 6 位一组二进制取出来,跟上面的操作差不多,就略过了,最后在编码结果后面加上 =,表示多出两个字符。
Base64 解码的过程
解码其实是编码的逆操作。
编码时:
- 将每个字符的 ASCII 的二进制排列在一起
- 以 6 位一组二进制进行拆分
- 将 6 位二进制转为 Base64 字符
解码时:
- 将每个 Base64 字符 的 ASCII 值转为对应的 Base64 数值(Index)
- 将转换后的数值的二进制排列在一起
- 以 8 位一组二进制进行拆分
- 将 8 位二进制(其值是 ASCII 值)通过 chr() 函数转为字符
先根据末尾的 = 来判断补齐了几位,如果进行了补齐处理,将末尾的 4 个字符截取出来,在最后进行处理,使得前面剩余的字符可以 4 个字符一组。
比如 MTIzNA==,截取末尾的 4 个字符 NA==,剩余的 MTIz 可以组成一组。MTIzNDU= 截取末尾的 4 个字符 NDU=,剩余的 MTIz 组成一组。
假设现有 MTIzNA== 需要解码,截取末尾后剩余 MTIz。首先将每个字符的 ASCII 通过 base64CharToInt() 方法进行转换成对应的 Base64 数值(Index),再将转换后的 数值的二进制排列起来,排列时去除了每个素质的二进制的左侧两位,最终得到 00001100010011001000110011。
// M 的 ASCII 为 77,转换后的 ASCII 为 12,12 的二进制为 00001100
// T 的 ASCII 为 84,转换后的 ASCII 为 19,19 的二进制为 00010011
// I 的 ASCII 为 73,转换后的 ASCII 为 8,8 的二进制为 00001000
// z 的 ASCII 为 122,转换后的 ASCII 为 51,51 的二进制为 00110011
00001100000000000000000000 // 将 12 的二进制左移 18 位,
00010011000000000000 // 将 19 的二进制左移 12 位
00001100010011000000000000 // 位或后
00001000000000 // 将 8 的二进制左移 6 位
00001100010011001000000000 // 位或后
00110011 // 51 的二进制
00001100010011001000110011 // 位与后
这里的 00001100010011001000110011 共有 26 位,因为第一个字符的左侧两位并未被移除,将其与 16777215(二进制为 24 个 1)进行位与运算,使其变成 24 位的二进制 001100010011001000110011,但是操作前后的编码结果并未发生改变,所以这里猜测左侧的 00 可以忽略(或者说每个位的默认值就是 0)。
最终得到的 24 位二进制与编码时排列后的的二进制是一样的,所以接下来只需要按照 8 位一组进行分割就可以得到原文的 ASCII 值,再通过 chr() 函数获取 ASCII 值对应的字符。
// 排列后的二进制
001100010011001000110011
00110001 00110010 00110011
1 2 3
接下来处理补齐的部分 NA==,有两个 = 说明编码时补齐了 4 位,多出了一个字符。
将第一个字符左移 6 位,为第二个字符腾出位置,将第二个字符或放在第一个字符后面。
00001101 // N 对应的 Base64 数值为 13,13 的二进制为 00001101
00001101000000 // 左移 6 位后
00000000 // A 对应的 Base64 数值为 0,0 的二进制为 00000000
00001101000000 // 位或后
0000110100 // 右移 4 位后
同样得到的二进制 0000110100 左侧多了两个 0,原因与上面一样,这里最终得到的是 00110100,通过 chr() 函数获取对应的字符为 4。
所以 MTIzNA== 解码后的结果是 1234。
补齐 2 位的解码处理跟补齐4位差不多,这里就不重复了。
Base64 解码的代码实现
碍于篇幅长度这里就不讲解码的代码实现了,如果搞懂了上面的编码实现,那么阅读解码的代码也是没什么问题的,不懂的话可以配合文末的带注释的代码进行理解。
这里着重说一下 base64CharToInt() 方法。
在编码时,我们通过 normalToBase64Char() 方法将一个 6 位的二进制转成了 Base64 字符,这里的 6 位二进制所表示的值就是 Base64 数值,也就是映射表中的 Index。
所以 base64CharToInt() 方法就是将 Base64 字符转成 Base64 数值(Index)。
private static function base64CharToInt($num)
{
// 因为在转换为 base64 字符时加了相应的值
// 在解码时需要再减去
if ($num >= 65 && $num <= 90) {
// 65 == A
return ($num - 65);
} else if ($num >= 97 && $num <= 122) {
// 97 == a
return ($num - 97) + 26;
} else if ($num >= 48 && $num <= 57) {
// 48 == 0
return ($num - 48)+52;
} else if ($num == 43) {
// 43 == +
return 62;
} else {
return 63;
}
}
这里是根据 Base64 字符的 ASCII 值 ($num) 来判断加/减多少数值才能得到原来的值。
- 65 ~ 90 对应的是 A ~ Z。
- 97 ~ 122 对应的是 a ~ z。
- 48 ~ 57 对应的是 0 ~ 9。
- 43 对应的是 +,编码时 $num 为 62 就返回 +,所以解码时返回 62。
- 47 对应的是 /,编码时 $num 为 63 就返回 /,所以解码时返回 63。
可以对照着 normalToBase64Char() 部分来理解。
带注释的源码
注释中一些关于 字符 的描述需要联系代码来理解其本意。
比如在编码的注释中:
先将第一个字符左移16位,为剩下2个字符(每个字符8位)腾出16位的空间
实际上左移 16 位的值是第一个字符的 ASCII 值,并不是字符本身。
在解码的注释中:
将第一个字符左移 18 位,为后面的 3 个字符腾出位置
跟编码时一样,左移 18 位的并不是字符本身,而是第一个字符的 Base64 数值 的 ASCII 值。
class Base64
{
/**
* 将 6 位二进制表示的值转为 Base64 字符
* @param $num
* @return string
*/
private static function normalToBase64Char($num)
{
if ($num >= 0 && $num <= 25) {
return chr(ord('A') + $num);
} else if ($num >= 26 && $num <= 51) {
return chr(ord('a') + ($num - 26));
} else if ($num >= 52 && $num <= 61) {
return chr(ord('0') + ($num - 52));
} else if ($num == 62) {
return '+';
} else {
return '/';
}
}
/**
* 将 Base64 字符 的 ASCII 值转为对应的 Base64 数值(Index)
* @param $num
* @return int
*/
private static function base64CharToInt($num)
{
// 因为在转换为 base64字符时加了相应的值
// 在解码时需要再减去
if ($num >= 65 && $num <= 90) {
// 65 == A
return ($num - 65);
} else if ($num >= 97 && $num <= 122) {
// 97 == a
return ($num - 97) + 26;
} else if ($num >= 48 && $num <= 57) {
// 48 == 0
return ($num - 48)+52;
} else if ($num == 43) {
// 43 == +
return 62;
} else {
return 63;
}
}
public static function encode($content)
{
// 字符串长度
$len = strlen($content);
// 完整组合
$loop = intval($len / 3);
//剩余字符数,是否需要补齐
$rest = $len % 3;
//首先计算完整组合
for ($i = 0; $i < $loop; $i++) {
$base_offset = 3 * $i;
// 每次取3个字符,一个字符占8位,总共24位
// 先将第一个字符左移16位,为剩下2个字符(每个字符8位)腾出16位的空间
$int_24 = (ord($content[$base_offset]) << 16)
// 再将第二个字符左移8位,紧跟第一个字符后面
| (ord($content[$base_offset + 1]) << 8)
// 最后一个字符放在剩下的8位里面
| (ord($content[$base_offset + 2]) << 0);
// 0x3f 转为十进制是63,二进制值是 111111,这里的 0x3f 相当于是掩码
// 后面的每次位移运算都只取6位,就得到了4个数字
// 将 $int_24 向右移 18 位,得到 base64 第一个字符的二进制,也就是 $int_24 最左侧的 6 位
// 再通过 normalToBase64Char 方法将4个数字转成 base64 那张表对应的字符
// 通过 normalToBase64Char() 方法将6位的二进制转换为 base64 字符
$ret .= self::normalToBase64Char($int_24 >> 18);
$ret .= self::normalToBase64Char(($int_24 >> 12) & 0x3f);
$ret .= self::normalToBase64Char(($int_24 >> 6) & 0x3f);
$ret .= self::normalToBase64Char($int_24 & 0x3f);
}
// 如果字符串长度刚好是 3 的整数倍时,上面的 for 循环已经将字符串处理完了
// 不需要进行补齐处理
if ($rest == 0) {
return $ret;
} else if ($rest == 1) {
// 如果多出1个字符,此时需要补齐4位,使其可以拆分为两个6位的 base64 字符
$int_12 = ord($content[$loop * 3]) << 4;
// 向右移 6 位,剩余左侧 6 位
$ret .= self::normalToBase64Char($int_12 >> 6);
// 通过 0x3f (111111) 以掩码的方式取出右侧 6 位
$ret .= self::normalToBase64Char($int_12 & 0x3f);
$ret .= "==";
return $ret;
} else {
// 如果多出 2 个字符,需要补齐 2 位
// 先将多出来的第一个字符左移 8 位,为多出来的第二个字符腾出位置
// 然后再将整体向左移 2 位,使其可以拆分为 3 个 6 位的 base64 字符
$int_18 = ((ord($content[$loop * 3]) << 8) | ord($content[$loop * 3 + 1])) << 2;
// 右移 12 位,剩余左侧 6 位
$ret .= self::normalToBase64Char($int_18 >> 12);
// 右移 6 位,通过 0x3f (111111) 以掩码的方式取出剩余的右侧 6 位
$ret .= self::normalToBase64Char(($int_18 >> 6) & 0x3f);
// 通过 0x3f (111111) 以掩码的方式取出右侧 6 位
$ret .= self::normalToBase64Char($int_18 & 0x3f);
$ret .= "=";
return $ret;
}
}
public static function decode($content)
{
$len = strlen($content);
if ($content[$len - 1] == '=' && $content[$len - 2] == '=') {
//说明加密的时候,剩余1个字节,补齐了4位,也就是左移了4位,所以除了最后包含的2个字符,前面的所有字符可以4个字符一组
$last_chars = substr($content, -4);
$full_chars = substr($content, 0, $len - 4);
$type = 1;
} else if ($content[$len - 1] == '=') {
//说明加密的时候,剩余2个字节,补齐了2位,也就是左移了2位,所以除了最后包含的3个字符,前面的所有字符可以4个字符一组
$last_chars = substr($content, -4);
$full_chars = substr($content, 0, $len - 4);
$type = 2;
} else {
$type = 3;
$full_chars = $content;
}
//首先处理完整的部分
$loop = strlen($full_chars) / 4;
$ret = "";
for ($i = 0; $i < $loop; $i++) {
$base_offset = 4 * $i;
// 每次取 4 个 base64 字符,一个字符占 6 位,总共 24 位
// 将第一个字符左移 18 位,为后面的 3 个字符腾出位置
$int_24 = (self::base64CharToInt(ord($full_chars[$base_offset])) << 18)
// 将第二个字符左移 12 位,紧跟在第一个字符后面
| (self::base64CharToInt(ord($full_chars[$base_offset + 1])) << 12)
// 将第三个字符左移 8 位,紧跟在第二个字符后面
| (self::base64CharToInt(ord($full_chars[$base_offset + 2])) << 6)
// 将第四个字符放在第三个字符后面
| (self::base64CharToInt(ord($full_chars[$base_offset + 3])) << 0);
// 右移 16 位,得到解码后第一个字符(24 - 16 = 8)
$ret .= chr($int_24 >> 16);
// 右移 8 位,再通过掩码 0xff(11111111) 得到解码后的第二个字符
$ret .= chr(($int_24 >> 8) & 0xff);
// 通过掩码 0xff(11111111) 得到最后一个字符
$ret .= chr($int_24 & 0xff);
}
//紧接着处理补齐的部分
if ($type == 1) {
// 多出一个字符
// 先将补齐的第一个字符左移 6 位,给第二个字符腾出位置
$int_12 = self::base64CharToInt(ord($last_chars[0])) << 6;
// 将第二个字符放入刚腾出来位置中,再将整体右移 4 位,保留 8 位,正好一个十进制数
$int_8 = ($int_12 | self::base64CharToInt(ord($last_chars[1]))) >> 4;
// 再根据 ASCII 值获取字符
$ret .= chr($int_8);
} else if ($type == 2) {
// 多处两个字符
// 首先将补齐的第一个字符左移 12 位,为剩余的两个字符腾出位置
$l_two_chars = ((self::base64CharToInt(ord($last_chars[0])) << 12)
// 将第二个字符左移 6 位,放在第一个字符的后面
| (self::base64CharToInt(ord($last_chars[1])) << 6)
// 将第三个字符放在剩余的 6 位中
// 将整体右移 2 位,此时正好 16 位,两个字符的长度
| (self::base64CharToInt(ord($last_chars[2])) << 0)) >> 2;
// 左移 8 位得到解码的第一个字符
$ret .= chr($l_two_chars >> 8);
// 通过 0xff(11111111) 作为掩码,得到右侧剩余的 8 位
$ret .= chr($l_two_chars & 0xff);
}
return $ret;
}
}
最后
原本在写完注释后,觉得对于 Base64 的实现已经理解的差不多了,但是在写这篇文章的时候,发现之前一些自认为理解的逻辑没办法写出来,主要原因还是没有理解透彻,所以在写的时候不能行云流水。
因为疫情的原因延期上班,公司是内网开发,没办法远程办公,所以就变成了延长放假时间。
每天日夜颠倒,看电影打游戏,三四个小时放不下手机。整个人变成了废柴状态,食不知味,玩不尽兴,内心极度焦虑。
直到我拿出笔记本,绞尽脑汁的写着这篇文章,我的焦虑、迷茫、空虚才找到了出口。