最近我在微信上看到了一篇介绍 rosedb 的文章,从这篇文章中,我了解到 rosedb 是一个基于 Bitcask 存储模型的 KV 存储引擎,并在此基础上做了大量了优化工作,它兼容 Redis 协议、支持丰富的数据结构和批量操作。实际上,可以将 rosedb 看作是 Go 语言版本的 Redis。
为了更深入地了解 Bitcask 是什么,我开始在 Google 上搜索相关资料,而这篇文章恰好排在搜索结果的前几位。文章详细介绍了 Bitcask 的关键实现细节,我觉得这篇文章可以帮助我们快速地了解 Bitcask,于是决定将其翻译成中文。
原文链接:https://arpitbhayani.me/blogs/bitcask/
Bitcask 是专为处理生产级流量而设计的、最高效的嵌入式键值(KV)数据库之一。介绍 Bitcask 的论文称它是一个用于快速键值的日志结构哈希表,用更简单的话来说,这意味着数据会被按顺序写入到仅附加日志文件中,并且每个键都会有一个指向其日志条目所在位置的指针。基于仅附加日志文件构建 KV 存储,这看起来似乎是一个非常奇怪的设计选择,但是 Bitcask 不仅提高了效率,而且还提供了非常高的读写吞吐量。
Bitcask 被引入作为一个名为 Riak 的分布式数据库的后端,其中每个节点都运行了一个 Bitcask 实例来保存它所负责的数据。在这篇文章中,我们将会深入研究 Bitcask 及其设计,并找到使其性能如此出色的秘诀。
Bitcask 的设计
Bitcask 使用了很多日志结构文件系统的原理,并从许多涉及日志文件合并的设计中汲取了灵感,例如 LSM 树的合并。从本质上来说,它就是一个具有固定结构和内存索引的仅附加(日志)文件的目录,内存索引中保存了键映射到点查找所需的大量信息(指数据文件中的条目)。
点查找(Point lookup)是指一次获取单个键值。类似的还有范围查找(Range lookup),是指一次获取多个键值。
数据文件
数据文件是一个仅附加日志文件,用来保存键值对以及一些元信息。单个 Bitcask 实例可以有很多个数据文件,但其中只会有一个数据文件处于活跃状态并打开用于写入操作,而其它数据文件则被认为是不可变的,仅用于读取操作。
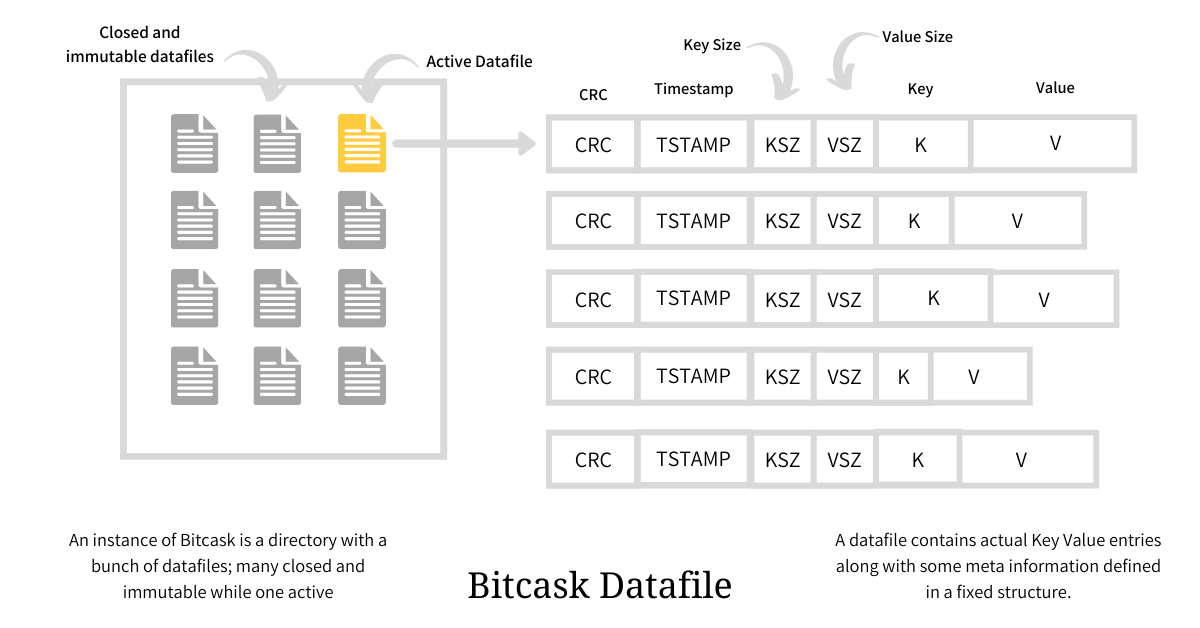
如上图所示,数据文件中的每个条目都有一个固定的结构,其中存储了 crc、timestamp、key_size、value_size、实际的 key、实际的 value。在引擎上的所有写操作(创建、更新、删除)都会转换为活跃数据文件中的条目。当这个活跃的数据文件的大小达到阈值时,它将会被关闭并创建一个新的处于活跃状态的数据文件;正如前面说的那样,当数据文件被关闭时(无论是有意或无意),就会被认为是不可变的,并且永远都不会再次打开用于写入操作。
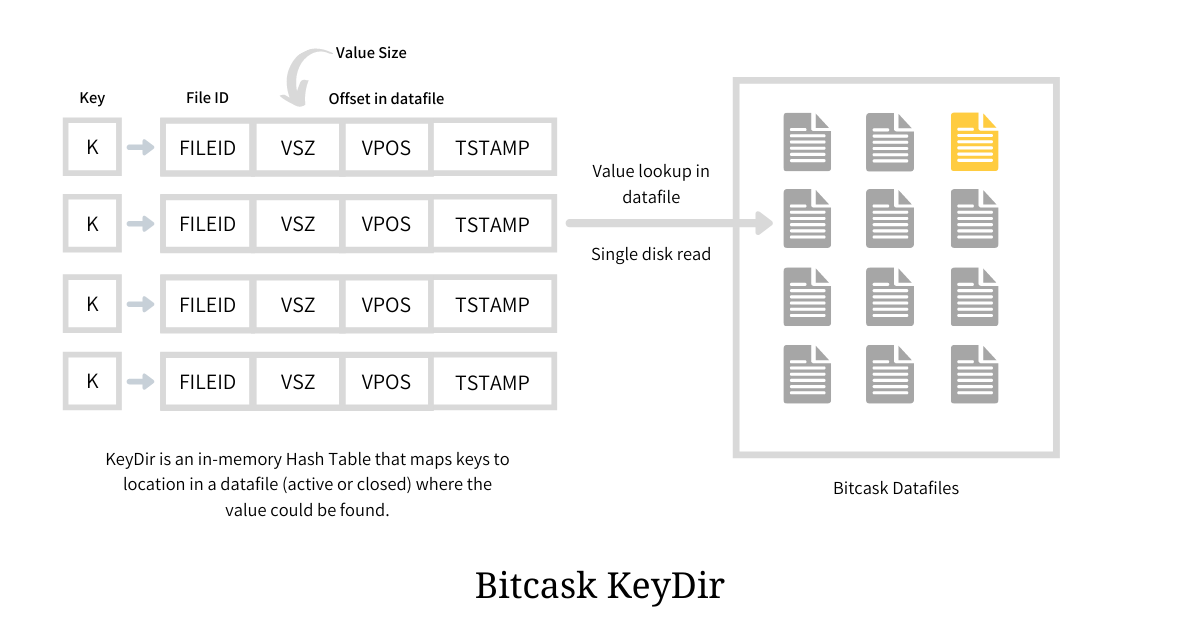
键目录
键目录是一个内存哈希表,它存储了 Bitcask 实例中存在的所有键,并将其映射到日志条目(值)所在的数据文件中的偏移量;从而使点查找更加方便。哈希表中的映射值是一个包含 file_id、offset 和一些元信息(例如 timestamp )的结构体,如下图所示。
Bitcask 上的操作
现在我们已经了解了 Bitcask 的整体设计和组件,我们可以开始探索它支持的操作及其实现的细节。
创建新的键值
当一个新的键值对被提交并保存到 Bitcask 时,引擎首先会将它追加到活跃的数据文件中,然后在键目录中创建一个新的条目,并指定存储该值的偏移量和文件。这两个操作都是以原子方式执行的,意味着要么在两个结构中都创建条目,要么都不创建。
创建一个新的键值对只需要一个原子操作,包含了一次磁盘写入和几次内存访问和更新。由于活跃的数据文件是一个仅附加文件,因此磁盘写入操作不必执行任何磁盘寻址,使写入操作以最佳速率进行,从而提供高写入吞吐量。
更新已存在的键值
该键值存储不支持部分更新,开箱即用,但是它支持整值替换。因此,更新操作与创建一个新的键值对非常相似,唯一的不同是不在键目录中创建条目,而是用新的位置更新已存在的条目,新的位置可能是在新的数据文件中。
与旧值对应的条目现在处于悬挂状态,并且将会在合并和压缩的过程中显式地进行垃圾回收。
删除键
删除键是一种特殊的操作,其中引擎以原子方式在活跃的数据文件中追加一个新条目,该条目的值等于墓碑值(表示删除),并从内存中的键目录中删除该条目。需要选择一个非常特别的值作为墓碑值,这样才不会让它干扰现有的值空间。
与更新操作一样,删除操作非常的轻量级,需要磁盘写入和内存更新。同样在删除操作中,与已删除的键相对应的旧条目将保持悬挂状态,并且将会在合并和压缩的过程中显式地进行垃圾回收。
读取键值
从存储中读取键值对,首先需要引擎找到数据文件以及提供的键在其中的偏移量;这个步骤是使用键目录完成的。一旦该信息是有效的,引擎就会从相应数据文件的偏移量处执行一次磁盘读取,以检索日志条目。根据存储的 CRC 对检索到的值进行正确性检查,然后将该值返回给客户端。
从本质上来说,该操作的速度很快,因为它只需要一次磁盘读取和几次内存访问,但使用文件系统预读缓存可以使其速度更快。
合并和压缩
正如我们在更新和删除操作期间所看到的,与键相对应的旧条目会保持不变并处于悬挂状态,这会导致 Bitcask 消耗了大量的磁盘空间。为了提高磁盘利用率,引擎每隔一段时间就会将已关闭的、旧的数据文件压缩到一个或多个与现有数据文件结构一致的合并文件中。
合并过程会遍历 Bitcask 中的所有不可变文件,并生成一组数据文件,这些数据文件仅包含当前每个键的实时和最新版本。这样,在新数据文件中将会忽略未使用和不存在的键,从而节省大量的磁盘空间。由于记录现在存储于不同的合并数据文件中,并且位于新的偏移量,因此需要对键目录中条目进行原子更新。
快速启动
如果 Bitcask 发生故障并需要重新启动,它必须读取所有的数据文件并构建一个新的键目录。在这里合并和压缩确实是有所帮助的,因为它减少了读取一些最终将会被驱逐的数据的需要。但还有另一种操作可以帮助加快启动时间。
为每个数据文件创建一个提示文件,它保存了数据文件中除了值以外的所有内容(键和相应的元信息)。因此,这个提示文件只是一个包含对应数据文件中所有键的文件。由于提示文件非常小,因此通过读取该文件,引擎可以快速地创建整个键目录并更快地完成启动过程。
Bitcask 的优点和缺点
优点
- 读写操作低延迟。
- 高写入吞吐量。
- 一次磁盘 IO 可以检索任意值。
- 可预测的查找和插入性能。
- 故障恢复快速且稳定。
- 备份简单,只需要拷贝目录即可。
缺点
键目录必须在内存中维护所有的键,这给系统增加的巨大的限制,因为它需要有足够的内存来容纳整个键空间以及文件系统缓冲区等其他必需品。因此,Bitcask 的限制因素是可用于保存键目录的 RAM 有限。
尽管看起来这个缺点很严重,但解决方案相当简单。通常情况下,我们可以对键进行分片并水平扩展,而不会对创建、读取、更新和删除等基本操作造成太大损失。