原文:Separation Anxiety: A Tutorial for Isolating Your System with Linux Namespaces
随着 Docker、Linux Containers 这些工具的出现,将 Linux 进程隔离到自己的小系统环境中隔离变得非常容易。这使得在一台真实的 Linux 机器上运行各种各样的应用成为可能,并确保它们之间不会互相干扰,而无需使用额外的虚拟机。这些工具为 PaaS 服务商带来了巨大的福音。但是这背后到底是如何实现的呢?
这些工具依赖于 Linux 内核的许多功能和组件。其中一些功能是最近才引入的,而另一些则仍然需要你为内核本身打补丁才能正常使用。但其中一个关键组件,即使用 Linux 命名空间,该组件自 2008 年 2.6.24 版本发布以来就一直是 Linux 的功能。
在本文中我们将介绍基础知识:什么是 Linux 命名空间、它们的用途是什么以及如何创建 Linux 命名空间?任何一个熟悉 chroot 的人应该都对 Linux 命名空间的功能以及通常如何使用命名空间具有基本的了解。就像 chroot 允许进程将任意目录视为系统根目录(独立于其它进程)一样,Linux 命名空间还允许进程独立修改操作系统的其它内容,这包括进程树、网络接口、挂载点、进程间通信资源等等。
为什么使用 Linux 命名空间进行进程隔离?
什么是 Linux 的命名空间?为什么要使用命名空间?在单用户计算机中,单一系统环境可能没有问题。但在服务器上,如果想要运行多个服务,则必须尽可能将这些服务互相隔离,这对于安全性和稳定性至关重要。想象在一台服务器上运行了多个服务,其中一个服务被入侵者破坏了。在这种情况下,入侵者也许可以利用该服务入侵其它服务,甚至可能危及整个服务器。命名空间隔离可以提供一个安全的环境来消除这种风险。
举个例子,使用命名空间可以在服务器上安全地执行任意或未知的程序。最近像 HackerRank、TopCoder、Codeforces 这样编程竞赛和「黑客马拉松」平台越来越多,这些平台大多数都利用了自动化流水线来运行和验证参赛者提交的程序。通常我们不可能提前知道参赛者提交的程序的真实性质,有些甚至可能包含恶意元素。通过在与系统其它部分完全隔离的命名空间中运行这些程序,对这些程序进行测试和验证,而不会使机器的其它部分面临风险。同理,在线持续集成服务(例如 Drone.io)会自动拉取你的代码仓库并在他们自己的服务器上运行测试脚本。同样,命名空间隔离使得安全地提供这些服务成为可能。
像 Docker 这样的命名空间工具还可以更好的控制进程对系统资源的使用,这使得此类工具备受 PaaS 服务商的欢迎。Heroku 和 Google App Engine 等服务使用此类工具在同一真实硬件上隔离和运行多个 Web 服务器应用程序。这些工具使它们可以运行每个应用程序(可能是由任何一个用户部署的),而无需担心某个程序占用太多系统资源,或者与同一台机器上部署的其它服务发生干扰或冲突。通过这种进程隔离,甚至可以为不同的隔离环境提供完全不同的依赖软件栈和版本。
如果你使用过 Docker 这样的工具,你应该已经知道了这些工具能够在小型「容器」中隔离进程。在 Docker 容器中运行进程,就像在虚拟机中运行它们一样,只是这些容器比虚拟机轻得多。虚拟机通常在操作系统上模拟硬件层,然后在硬件层上运行另一个操作系统。这样就可以在虚拟机内运行进程,与真实操作系统完全隔离。但是虚拟机太重了!在 Docker 容器中,使用了真实操作系统的命名空间和其它一些关键功能,确保提供与虚拟机类似的隔离级别,但无需模拟硬件和在同一台机器上运行另一个操作系统。这使得 Docker 容器非常轻量级。
进程命名空间
一直以来,Linux 内核只维护一个进程树。该进程树包含运行在当前父子层次结构中每个进程的引用。一个进程只要有足够的权限并满足某些条件,就可以向另一个进程附加跟踪器来检查它,甚至可以杀死它。
通过引入 Linux 命名空间,使得拥有多个「嵌套的」进程树成为可能。每个进程树都可以拥有一组完全隔离的进程。这可以确保属于一个进程树的进程无法被检查或杀死,事实上甚至无法知道其它同级或父级进程树中进程的存在。
每次启动装有 Linux 的计算机时,它都只会启动一个进程,进程标识符(PID)为 1。该进程是进程树的根,它通过执行适当的维护工作和启动正确的守护进程/服务来启动系统的其余部分。所有其它进程都从进程树中这个进程的下面开始。PID 命名空间允许我们用自己的 PID 1 进程分拆出一颗新的进程树。这样做的进程仍然保留在父命名空间的原始进程树中,但会使子进程成为其自身进程树的根。
通过 PID 命名空间隔离,子命名空间的进程无法知道父进程的存在。然而,父命名空间的进程具有子命名空间中进程的完整视图,就像它们是父命名空间中任何其它进程一样。
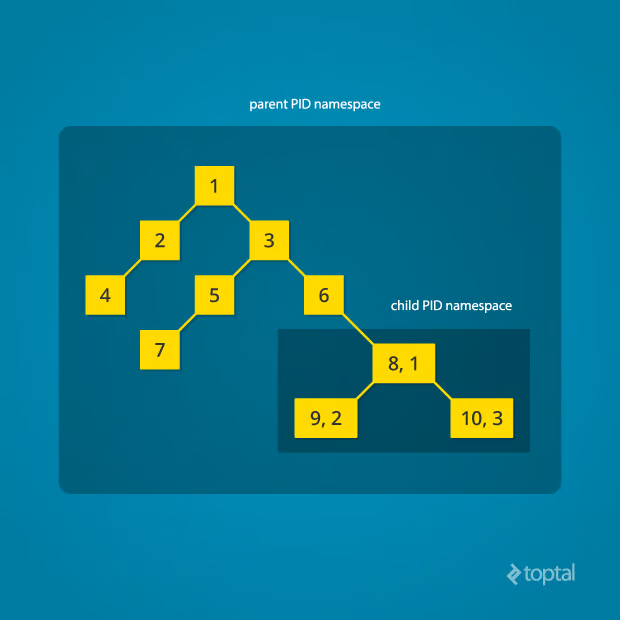
创建一系列嵌套的子命名空间:一个进程在一个新的 PID 命名空间中启动一个子进程,该子进程又在一个新的 PID 命名空间中产生另一个进程,以此类推。
通过引入 PID 命名空间,单个进程现在可以有多个与其关联的 PID,每个 PID 都对应于它所属的命名空间。在 Linux 源代码中,我们可以看到名为 pid 的结构体过去只能跟踪一个 PID,现在可以通过名为 upid 的结构体来跟踪多个 PID:
struct upid {
int nr; // the PID value
struct pid_namespace *ns; // namespace where this PID is relevant
// ...
};
struct pid {
// ...
int level; // number of upids
struct upid numbers[0]; // array of upids
};
为了创建一个新的 PID 命名空间,必须使用特殊标志 CLONE_NEWPID 调用 clone() 系统调用(C 提供了一个包装器来暴露该系统调用,许多其它流行的语言也是如此)。下面讨论的其它命名空间也可以使用 unshare() 系统调用创建,而 PID 命名空间只能在使用 clone() 产生新进程时创建。一旦使用该标志调用 clone(),新进程就会立即在新进程树下的新 PID 命名空间中启动。这可以使用一个简单的 C 程序来演示:
#define _GNU_SOURCE
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
static char child_stack[1048576];
static int child_fn() {
printf("PID: %ld\n", (long)getpid());
return 0;
}
int main() {
pid_t child_pid = clone(child_fn, child_stack+1048576, CLONE_NEWPID | SIGCHLD, NULL);
printf("clone() = %ld\n", (long)child_pid);
waitpid(child_pid, NULL, 0);
return 0;
}
使用 root 权限编译并运行该程序,你将会注意到类似于以下内容的输出:
clone() = 5304
PID: 1
从 child_fn 打印出来的 PID 为 1。
尽管上面的示例代码并不比某些语言的「Hello world」长多少,但其幕后发生了很多事情。 正如你预期的那样,clone() 函数通过克隆当前进程创建了一个新进程,并在 child_fn() 函数的开头处开始执行。然而,在这样做的同时,它将新进程从原始进程树中分离出来,并为新进程创建了一个单独的进程树。
尝试用以下代码替换 static int child_fn() 函数,从隔离进程的视角打印父 PID:
static int child_fn() {
printf("Parent PID: %ld\n", (long)getppid());
return 0;
}
请注意,从隔离进程的视角来看,父 PID 为 0,表示没有父进程。尝试再次运行相同的程序,但这一次,从 clone() 函数调用中删除 CLONE_NEWPID 标志:
pid_t child_pid = clone(child_fn, child_stack+1048576, SIGCHLD, NULL);
这次,你将会注意到父 PID 不再是 0:
clone() = 11561
Parent PID: 11560
然而,这只是本文的第一步。这些进程仍然可以不受限制地访问其它公共或共享资源。例如,网络接口:如果上面创建的子进程要监听 80 端口,它将阻止系统上所有其它进程监听该端口。
网络命名空间
这就是网络命名空间发挥作用的地方。网络命名空间允许每个进程看到一组完全不同的网络接口。甚至每个网络命名空间的环回接口也是不同的。
将进程隔离到它自己的网络命名空间,这需要介绍 clone() 系统调用的另一个标志:CLONE_NEWNET:
#define _GNU_SOURCE
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
static char child_stack[1048576];
static int child_fn() {
printf("New `net` Namespace:\n");
system("ip link");
printf("\n\n");
return 0;
}
int main() {
printf("Original `net` Namespace:\n");
system("ip link");
printf("\n\n");
pid_t child_pid = clone(child_fn, child_stack+1048576, CLONE_NEWPID | CLONE_NEWNET | SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
return 0;
}
输出:
Original `net` Namespace:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp4s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:24:8c:a1:ac:e7 brd ff:ff:ff:ff:ff:ff
New `net` Namespace:
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
这里发生了什么?物理以太网设备 enp4s0 属于全局网络命名空间,从该命名空间运行「ip」 工具可以看出这一点。然而,物理接口在新的网络命名空间中并不可用。此外,环回设备在原始网络命名空间中处于活跃状态,但在子网络命名空间中处于「关闭」状态。
为了在子网络命名空间中提供可用的网络接口,则必须设置跨多个命名空间的额外「虚拟」网络接口。一旦完成,就可以创建以太网桥,甚至可以在命名空间之间路由数据包。最后,为了使整个工作正常进行,必须在全局网络命名空间运行「路由进程」以接收来自物理接口的流量,并通过合适的虚拟接口将它路由到正确的子网络命名空间。看到这里,也许你能理解为什么像 Docker 这样能帮你完成所有这些繁重工作的工具如此受欢迎了!
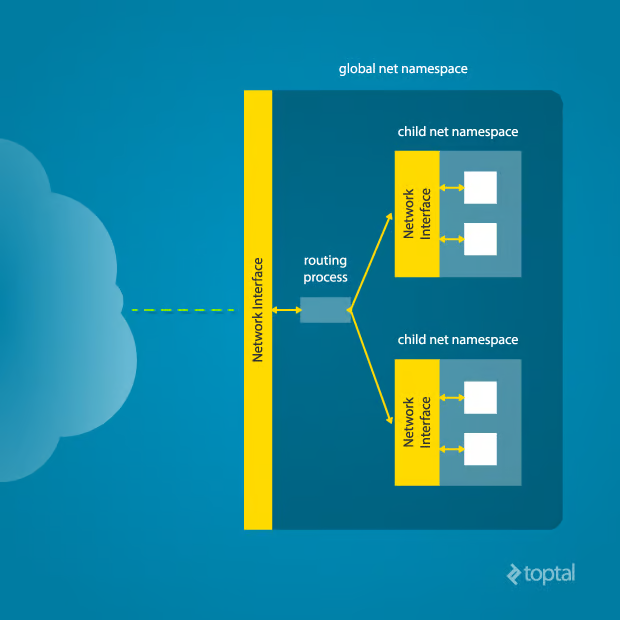
需要手动执行该操作,你可以通过从父命名空间运行单个命令在父命名空间和子命名空间之间创建一对虚拟以太网连接:
ip link add name veth0 type veth peer name veth1 netns <pid>
此处 <pid> 应该替换为在父命名空间观察到的子命名空间中进程的进程 ID。运行此命令会在这两个命名空间之间建立类似管道的连接。父命名空间会保留 veth0 设备,并将 veth1 设备传递给子命名空间。任何进入一端的东西都会从另一端出来,就像你对两个真实节点之间的真实以太网连接所期望的那样。因此,必须为该虚拟以太网连接的两端分配 IP 地址。
挂载命名空间
Linux 同样也为系统所有挂载点维护了一个数据结构。它包括像挂载了哪些磁盘分区、它们被挂载到了哪里、是否只读等信息。有了 Linux 命名空间,就可以克隆这一数据结构,这样不同命名空间下的进程就可以改变挂载点,而不会互相影响。
创建单独的挂载命名空间的效果类似于使用 chroot()。虽然 chroot 很好,但是它不能提供完整的隔离,其效果仅限于根挂载点。创建单独的挂载命名空间允许每个隔离进程对整个系统的挂载点结构具有与原始挂载点结构完全不同的视图。这允许你让每个隔离进程拥有不同的根,以及特定于这些进程的其它挂载点。根据本文谨慎使用,可以避免暴露底层系统的任何信息。
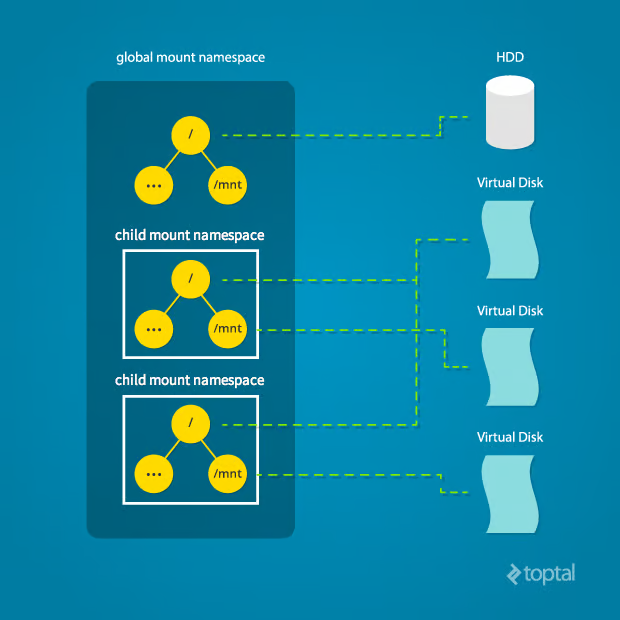
为了实现此目的,clone() 所需的标志是 CLONE_NEWNS:
clone(child_fn, child_stack+1048576, CLONE_NEWPID | CLONE_NEWNET | CLONE_NEWNS | SIGCHLD, NULL)
最初,子进程看到与父进程完全相同的挂载点。然而,在新的挂载命名空间下,子进程可以挂载或卸载任何它想要的端点,并且更改不会影响父进程的命名空间,也不会影响整个系统中任何其它的挂载命名空间。例如,如果父进程在根目录挂在了一个特定的磁盘分区,则隔离进程一开始就会看到在根目录下挂载的完全相同的磁盘分区。但是,当子进程出尝试将根分区更改为其它分区时,挂载命名空间隔离的好处就很明显了,因为更改只会影响隔离的挂载命名空间。
有趣的是,这实际上使得直接使用 CLONE_NEWNS 标志创建目标子进程成为一个坏主意。更好的方式是使用 CLONE_NEWNS 标志启动一个特殊的「init」进程,让该「init」进程根据需要修改 /、/proc、/dev 或其它挂载点,然后再启动目标进程。在本文的末尾,我们将对此进行更详细的讨论。
其它命名空间
这些进程还可以被隔离到其它命名空间中,即用户、IPC 和 UTS。用户命名空间允许一个进程在命名空间中拥有 root 权限,但不允许进程访问命名空间外的进程。通过 IPC 命名空间隔离进程可以为其提供自己的进程间通信资源,例如,System V IPC 和 POSIX 消息。UTS 命名空间隔离了系统的两个特殊标识符:nodename 和 domainname。
下面是一个展示 UTS 命名空间如何隔离的简单示例:
#define _GNU_SOURCE
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/utsname.h>
#include <sys/wait.h>
#include <unistd.h>
static char child_stack[1048576];
static void print_nodename() {
struct utsname utsname;
uname(&utsname);
printf("%s\n", utsname.nodename);
}
static int child_fn() {
printf("New UTS namespace nodename: ");
print_nodename();
printf("Changing nodename inside new UTS namespace\n");
sethostname("GLaDOS", 6);
printf("New UTS namespace nodename: ");
print_nodename();
return 0;
}
int main() {
printf("Original UTS namespace nodename: ");
print_nodename();
pid_t child_pid = clone(child_fn, child_stack+1048576, CLONE_NEWUTS | SIGCHLD, NULL);
sleep(1);
printf("Original UTS namespace nodename: ");
print_nodename();
waitpid(child_pid, NULL, 0);
return 0;
}
该程序产生以下输出:
Original UTS namespace nodename: XT
New UTS namespace nodename: XT
Changing nodename inside new UTS namespace
New UTS namespace nodename: GLaDOS
Original UTS namespace nodename: XT
在这里,child_fn() 打印了 nodename,并将其改为其它内容,然后再次打印。当然,更改仅发生在新的 UTS 命名空间内。
关于所有命名空间提供和隔离的更多信息可以在该教程中找到。
跨命名空间通信
父命名空间和子命名空间之间通常需要建立某种通信。这可能是为了在隔离环境中进行配置工作,也可能只是为了保留从外部窥探该环境状况的能力。其中一种方法是在环境内部运行 SSH 守护进程。你可以在每个网络命名空间内安装一个单独的 SSH 守护进程。然而,运行多个 SSH 守护进程会使用大量宝贵的资源(例如内存)。这时,使用一个特殊的「init」进程再次被证明是一个好主意。
「init」进程可以在父命名空间和子命名空间之间建立通信通道。该通道可以基于 UNIX 套接字,甚至可以使用 TCP。要创建一个跨两个不同挂载命名空间的 UNIX 套接字,你需要先创建子进程,然后创建 UNIX 套接字,最后将子进程隔离到单独的挂载命名空间中。但是我们怎样才能先创建进程,然后再隔离它呢?Linux 提供了 unshare()。这个特殊的系统调用允许进程将自身与原始命名空间隔离,而不是让父进程先隔离子进程。例如,下面的代码与前面在网络命名空间提到的代码具有完全相同的效果:
#define _GNU_SOURCE
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
static char child_stack[1048576];
static int child_fn() {
// calling unshare() from inside the init process lets you create a new namespace after a new process has been spawned
unshare(CLONE_NEWNET);
printf("New `net` Namespace:\n");
system("ip link");
printf("\n\n");
return 0;
}
int main() {
printf("Original `net` Namespace:\n");
system("ip link");
printf("\n\n");
pid_t child_pid = clone(child_fn, child_stack+1048576, CLONE_NEWPID | SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
return 0;
}
由于「init」进程是你设计的,所以你可以先让它完成所有必要的工作,然后再执行目标子进程之前将其自身从系统其余部分隔离。
总结
本文概述了如何在 Linux 中使用命名空间,然后逐步解释了 Linux 命名空间。它将让你对 Linux 开发人员如何开始实施系统隔离(Docker 或 Linux 容器等工具架构中不可或缺的一部分)有一个基本概念。在大多数情况下,最好使用这些现成的工具之一,因为这些工具已经广为人知并且经过了大量的测试。但在某些情况下,拥有自己定制的进程隔离机制可能是有意义的,在这种情况下,本文将为你提供极大的帮助。
实际上,幕后发生的事情比我在本文中介绍的要多得多,并且你可能希望通过更多方法来限制你的目标进程以提高安全性和隔离性。不过,希望这篇文章能为那些有兴趣进一步了解 Linux 命名空间隔离如何真正发挥作用的人提供一个有用的起点。