不知不觉已经三个多月没有更新博客了,这段时间也想写一点东西,但因为各种原因一直没有动笔。或许我的拖延症已经到达晚期了 ¯\(ツ)/¯。最近,我看到一句挺有意思的话:「战胜拖延症的方法:我就是要做一坨🐶💩出来」。话虽糙,但其本质是「完成比完美更重要」。如果一开始就抱着把事情搞砸的心态去做,说不定就成了呢?

当然,这段时间我也没有闲着,大部分时间都在看极客时间的《陈天 · Rust 编程第一课》专栏。在掌握了基础知识之后,我迫不及待地想要用 Rust 写些小工具练练手,由于没有特别好的想法,我决定用 Rust 实现一些「短小精悍」的开源项目,比如 rosedblabs/wal。
「短小」指的是代码量方面,这个项目的代码量不多,核心逻辑大约只有几百行,这样一来实现起来不会太困难,比较容易落地。「精悍」则体现在功能方面,用几百行代码就实现了基于磁盘、支持并发读写的高性能预写日志库。所以选择它作为练手项目再合适不过了。

经过与 Rust 编译器的无数次斗争,我终于「磕磕绊绊」地完成了这个项目,并且通过了所有的单元测试。
为什么说是磕磕绊绊呢?因为在编码期间,多次由于代码无法通过编译,我一度想要暂时搁置这个项目。但每次总是在快要放弃的时候,又让我找到了解决方法,颇有一种「山重水复疑无路,柳暗花明又一村」的感觉。
我将项目代码放到了 GitHub:https://github.com/her-cat/wal-rs,如果你觉得不错,可以点个 star 哦~

接下来,我将通过 rosedblabs/wal 项目的 README.md 以及代码来介绍一下这个项目。
什么是 WAL?
WAL 是 Write Ahead Log 的简称,通常叫做预写日志,是一种用于防止内存崩溃、保证数据不丢失的手段。需要注意的是,WAL 是一种方法,而不是具体的实现形式,这意味着它可能会以不同的形式出现在各种项目中。
例如,在 Redis 中,有一种数据持久化方式叫做 AOF(Append Only File)。Redis 会将所有对数据库进行写入操作的命令以追加的方式写入到 AOF 文件中。当 Redis 重启时,它会读取 AOF 文件,通过重放所有写入命令来还原重启前的数据库状态,从而保证数据不会丢失。
RoseDB 是一个基于 Bitcask 的键值存储引擎,Bitcask 的数据文件也是一个仅附加的日志文件(Append Only File),因此,我们同样可以使用 WAL 作为 RoseDB 的底层存储,而 RoseDB 确实是这么做的。
关于 Bitcask,可以参考我之前翻译的文章:了解 Bitcask:基于日志结构的 KV 存储引擎
WAL 的整体设计
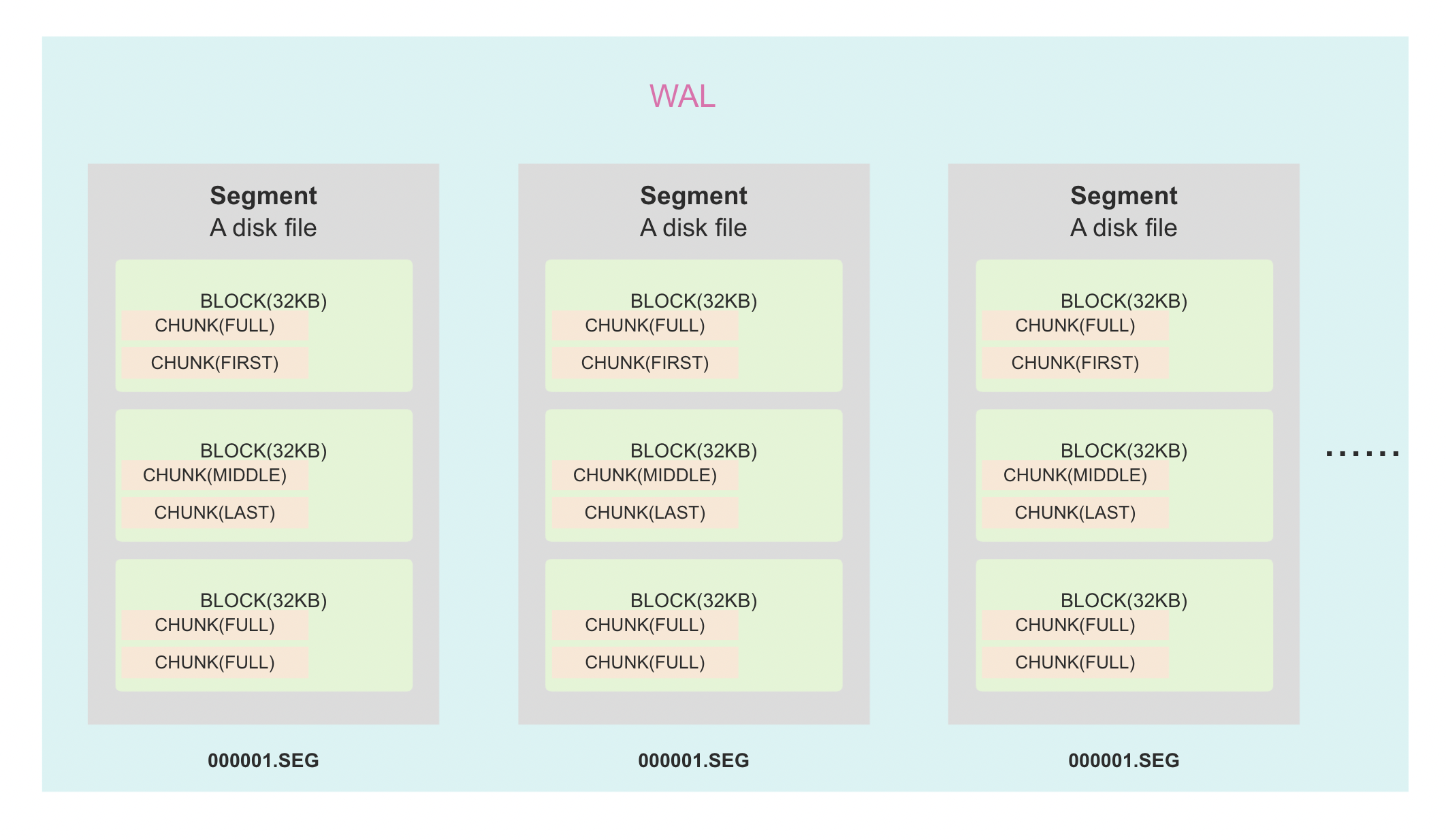
从上图可以看出,在一个 WAL 实例中,会有多个用于存储数据的文件(Segment),每个文件包含若干个块(Block),每个块的大小固定为 32KB。每个块中又包含若干个大小可变的 Chunk,每个 Chunk 包含 7 个字节的头部和用户实际存储的数据。Chunk 分为 FULL、FIRST、MIDDLE、LAST 四种类型,这里借鉴了 LevelDB 和 RocksDB 的设计。
关于 Chunk 类型的分配,如果当前块有足够的剩余空间可以容纳写入的数据(即块的剩余空间大于或等于数据的大小),Segment 会直接写入一条包含该数据的 Chunk,Chunk 类型为 FULL,表示该 Chunk 包含的是一条完整的数据。如果当前块无法完全容纳写入的数据(即块的剩余空间小于数据的大小),Segment 会将该数据分成多个 Chunk 进行写入。
- FIRST:表示该 Chunk 是数据的第一个部分。
- MIDDLE:表示该 Chunk 是数据的中间部分。
- LAST:表示该 Chunk 是数据的最后一个部分。
就像 Bitcask 那样,在一个 WAL 实例中,只会有一个活跃的 Segment 用于读写新数据,其它的 Segment 仅用于读取旧数据,接下来我们来看看 WAL 的写入和读取操作。
WAL 的写操作
对于写入操作,WAL 提供了 WAL::write 和 WAL::write_all 两个方法,前者用于写入单条数据,后者用于批量写入多条数据。
以下是 WAL::write 方法的主要流程:
- 获取 WAL 实例的写锁,避免并发修改 WAL 实例。
- 检查要写入的数据是否大于单个 Segment 的大小。
- 检查当前活跃的 Segement 的剩余空间是否能够容纳要写入的数据。
- 如果无法容纳,则调用
WAL::rotate_active_segment,将当前的活跃的 Segment 移动到旧的 Segment 中,并创建一个新的 Segment 作为活跃的 Segment。
- 如果无法容纳,则调用
- 调用活跃的 Segment 的
Segment::write写入数据,并得到该数据的ChunkPosition。 - 检查是否需要同步数据,如果需要,则调用活跃的 Segment 的
Segment::sync。 - 最后,返回
ChunkPosition。
在 Segment::write 中,首先会从 BUFFER_POOL 中获取一个可用的 Buffer,然后调用 Segment::write_to_buf,将数据以 Chunk 格式进行编码写入到 Buffer 中,最后调用 Segment::write_chunk_buf,将 Buffer 中的数据写入到 Segment 文件中。其中最核心的是 Segment::write_to_buf,它包含了数据填充、数据编码、更新块号及生成 ChunkPosition 等逻辑。
WAL::write_all 与 WAL::write 的流程大致相同,只不过写入数据时调用的是 Segment::write_all。该方法与 Segment::write 唯一不同的是,该方法会循环调用 Segment::write_to_buf,将所有数据以 Chunk 格式进行编码写入到 Buffer 中。
WAL 的读操作
当数据被写入后,我们可以通过 ChunkPosition 调用 WAL::read 读取数据,或者调用 WAL::new_reader 生成 Reader 来遍历所有数据。
以下是 WAL::read 方法的主要流程:
- 获取 WAL 实例的读锁,使得我们可以并发地进行读取操作。
- 判断
ChunkPosition.segment_id是否等于当前活跃的 Segment 的 id。- 等于:调用当前活跃的 Segment 的
Segment::read读取数据。 - 不等于:通过
ChunkPosition.segment_id从旧的 Segment 中找到相应的 Segment, 并调用Segment::read读取数据。
- 等于:调用当前活跃的 Segment 的
由于我们的数据在写入时,可能被分成了多个 Chunk,所以在 Segment::read 中,需要循环读取所有数据块并汇总:
- 调用
Segment::load_cache_block,尝试根据块号从缓存中读取相应块数据,如果不存在就从文件读取并缓存。 - 根据偏移量从块数据中读取 Chunk 的头部和数据部分,并检查校验和是否一致。
- 将数据部分追加到数据结果中。
- 如果 Chunk 类型是 FULL 或者 LAST,表示已经读取完毕,需要跳出循环;
- 否则,当前块号加一并重置当前偏移量,继续读取下一个 Chunk。
- 最后,返回数据结果。
总结
至此,关于 WAL 项目的介绍已经结束。在文章开头我提到过,这个项目的代码量并不多,因此我非常推荐大家去看看源代码。无论你是想学习 Rust 语言还是 WAL 的设计,看完之后一定会有所收获。
当然,如果你还能找到一些 Bug,那就更好了。 :-P
2024.06.05 更新:
目前,该项目已贡献给 rosedblabs/wal-rs,并由 rosedblabs 社区继续维护。her-cat/wal-rs 将不再更新。